KenLM: Small and Fast LM Inference
Up to the main page This page summarizes results from my paper KenLM: Faster and Smaller Language Model Queries and talk.Perplexity Task
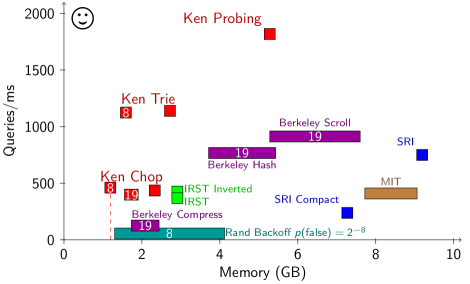
Performance computing the perplexity of Gigaword using the pruned model. Top left is best. Queries were converted to vocabulary identifiers in advance. Time to read files, including loading and file operations to read Gigaword, was subtracted. Resident memory was measured after loading and peak virtual memory was measured after scoring completed. For Ken, IRST, and SRI these were much the same and appear as a constant-width box. For MIT, Berkeley, and Rand, the left of the bar is resident after loading and the right is peak after scoring. The white number indicates level of quantization.
Decoding
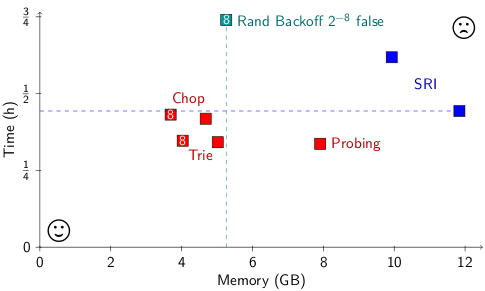
Cost to translate the 3003-sentence WMT 11 French-English test set using Moses on 8 cores.
Language Model
The 5-gram language model was trained on 834 million tokens from Europarl v6 and the 2011 Workshop on Machine Translation News Crawl corpus with duplicate lines removed. The pruned model (used in most comparisons) was built using SRILM with modified Kneser-Ney settings. We also built a RandLM Stupid Backoff model on the same training data. This does not prune so, to make the comparison fair, we also used IRSTLM to build an unpruned 5-gram model and use that when comparing to RandLM Stupid.Loading
In all cases, we converted to the model's binary format first. The binary file was loaded into memory (using cat >/dev/null) before launching the test.On BerkeleyLM
KenLM was publicly announced and distributed with Moses on 18 October 2010. This precedes both the 17 December 2010 submission deadline for the BerkeleyLM paper and their 20 June 2011 public release. Tests performed by Adam Pauls in May 2011 showed that KenLM is 4.49x faster. He omitted KenLM from his paper and his 20 June 2011 talk, claiming SRILM is the fastest package.
BerkeleyLM's paper (Pauls and Klein, 2011) claimed to be lossless. However, the code tested in that paper intentionally rounds up the floating-point mantissa to 12 bits (and only about 7 bits of exponent are used in practice). This made the memory usage numbers reported in the BerkeleyLM paper smaller than they should have been. For the KenLM paper, I compared with BerkeleyLM revision 152, documenting both the revision number and that it quantizes. Adam Pauls fixed his code afterwards and has posted an errata.