Fast and Accurate Decoding
This is an algorithm to search hypergraphs and lattices for high-scoring hypotheses, where the score includes a language model. It is an alternative to cube pruning. A description of the algorithm appears in my paperGrouping Language Model Boundary Words to Speed K-Best Extraction from HypergraphsIn short, every hypothesis has a language model state consisting of its leftmost and rightmost words. If two hypotheses have the same exact boundary words, then they may recombine as in cube pruning. However, many hypotheses share some, but not all, words. My algorithm exploits these common words to group hypotheses together. The groups are dynamically expanded in a best-first manner.
, Philipp Koehn, and Alon Lavie. NAACL HLT, Atlanta, Georgia, USA, 10—12 June, 2013.
[Paper] [BibTeX]
Performance
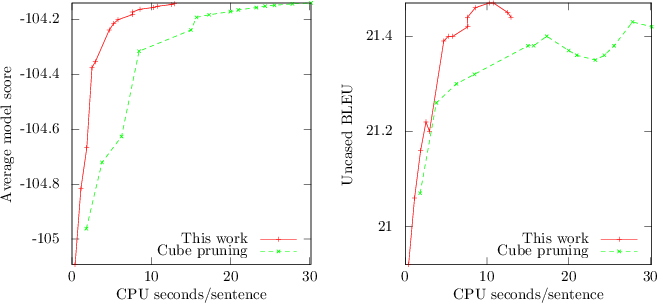
The plots below show single-threaded Moses performance on a German-English system with target syntax. Model scores have arbitrary scale and constant factors. Moses was compiled with recommended settings. Rest costs were used for the language model. The same set of beam sizes are shown, ranging from 5 to 1000.
Usage
- Moses Chart
-search-algorithm 5- cdec
--incremental_search lm.binary- Standalone
- Github download
- Your decoder
- The search/ directory is designed to be decoder-independent.
Implementation Limitations
- The language model must be the only stateful feature.
- Only one language model is allowed at a time.
- The language model must be queried with KenLM.
- K-best list extraction is done internally via a separate code path; logging and other analysis has not been ported.